Claude Code 记忆系统 — 使用指南
让 Claude Code 跨会话记住你是谁、你偏好什么、项目正在发生什么。
记忆系统 · 四种记忆类型 · 触发保存 · 存储位置 · 管理记忆 · 生命周期 · 快速参考
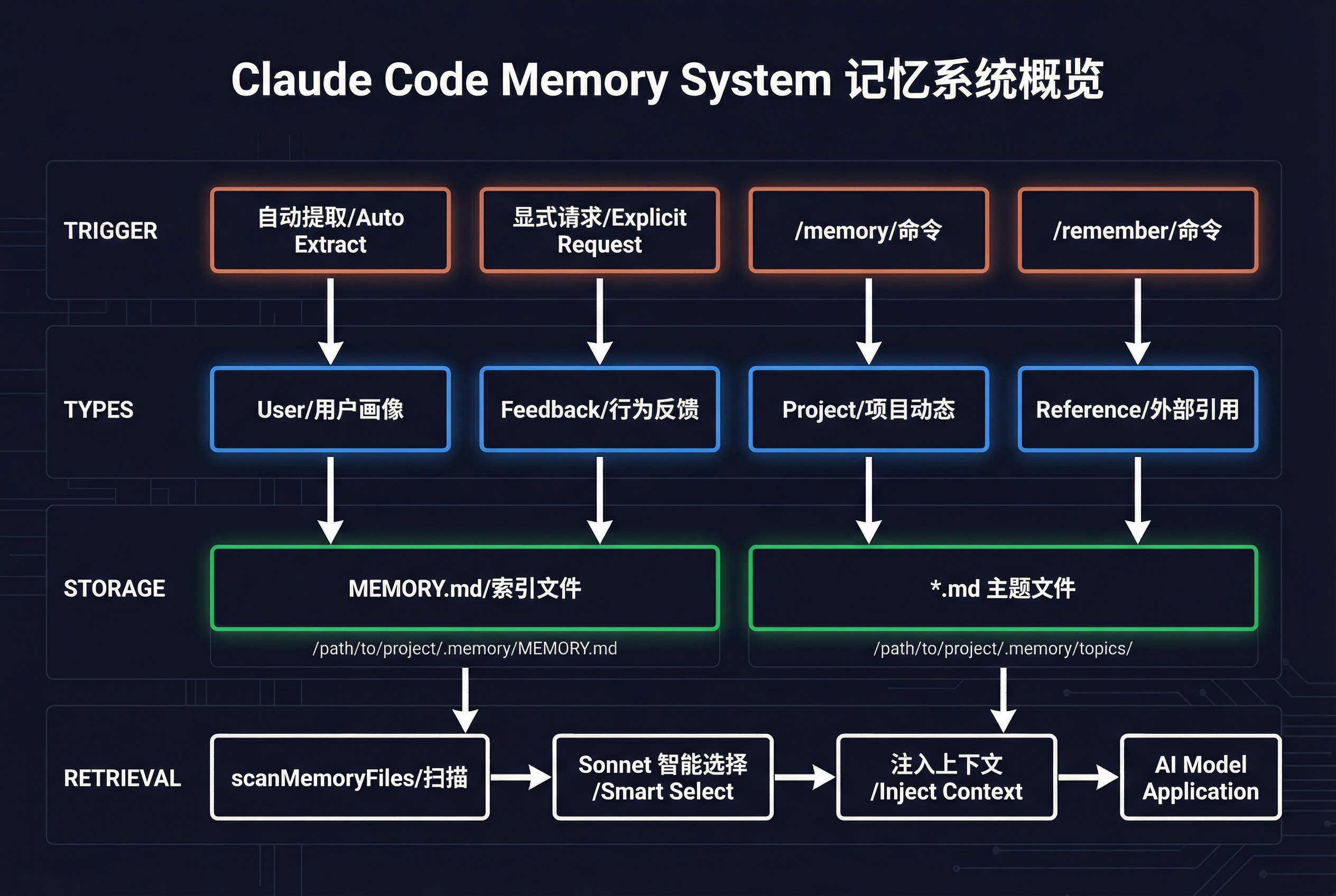
一、什么是记忆系统?
Claude Code 的记忆系统是一套基于文件的持久化知识库,让 Claude 能够跨越多次对话,持续积累对你和你的项目的理解。
核心理念:只记住无法从代码中推断出来的东西。
| 记住 | 不记住 |
|---|---|
| 你是数据科学家,关注日志系统 | 代码架构、文件结构 |
| "不要 mock 数据库" | Git 历史、谁改了什么 |
| 周四后冻结非关键合并 | 已有的 CLAUDE.md 内容 |
| Bug 跟踪在 Linear 的 INGEST 项目 | 调试方案(修复已在代码里) |
二、四种记忆类型

Claude Code 将记忆严格分为四类:
1. User(用户画像)
记录你的角色、目标、技能水平和偏好,帮助 Claude 调整协作方式。
用户说:我写了十年 Go,但这是第一次碰这个仓库的 React 部分
Claude 保存:深厚 Go 经验,React 新手 — 用后端类比解释前端概念2. Feedback(行为反馈)
你对 Claude 工作方式的纠正或肯定。这类记忆让 Claude 不会犯同样的错。
用户说:别在回复末尾总结你做了什么,我能看 diff
Claude 保存:用户要求简洁回复,不要尾部摘要重要:不只记录纠正,也记录肯定。如果 Claude 做了一个非显而易见的选择而你认可了,也会被记住。
3. Project(项目动态)
无法从代码或 Git 历史中推导出的项目上下文:谁在做什么、为什么、截止日期。
用户说:我们周四后冻结所有非关键合并,移动团队要切发布分支
Claude 保存:2026-03-05 起合并冻结,标记该日期后的非关键 PR 工作注意:Claude 会将相对日期("周四")转换为绝对日期("2026-03-05"),确保记忆不会过时失效。
4. Reference(外部引用)
指向外部系统中信息的指针:仪表板、工单系统、Slack 频道。
用户说:oncall 看的是 grafana.internal/d/api-latency 这个面板
Claude 保存:grafana.internal/d/api-latency 是 oncall 延迟仪表板 — 编辑请求路径代码时检查三、如何触发记忆保存
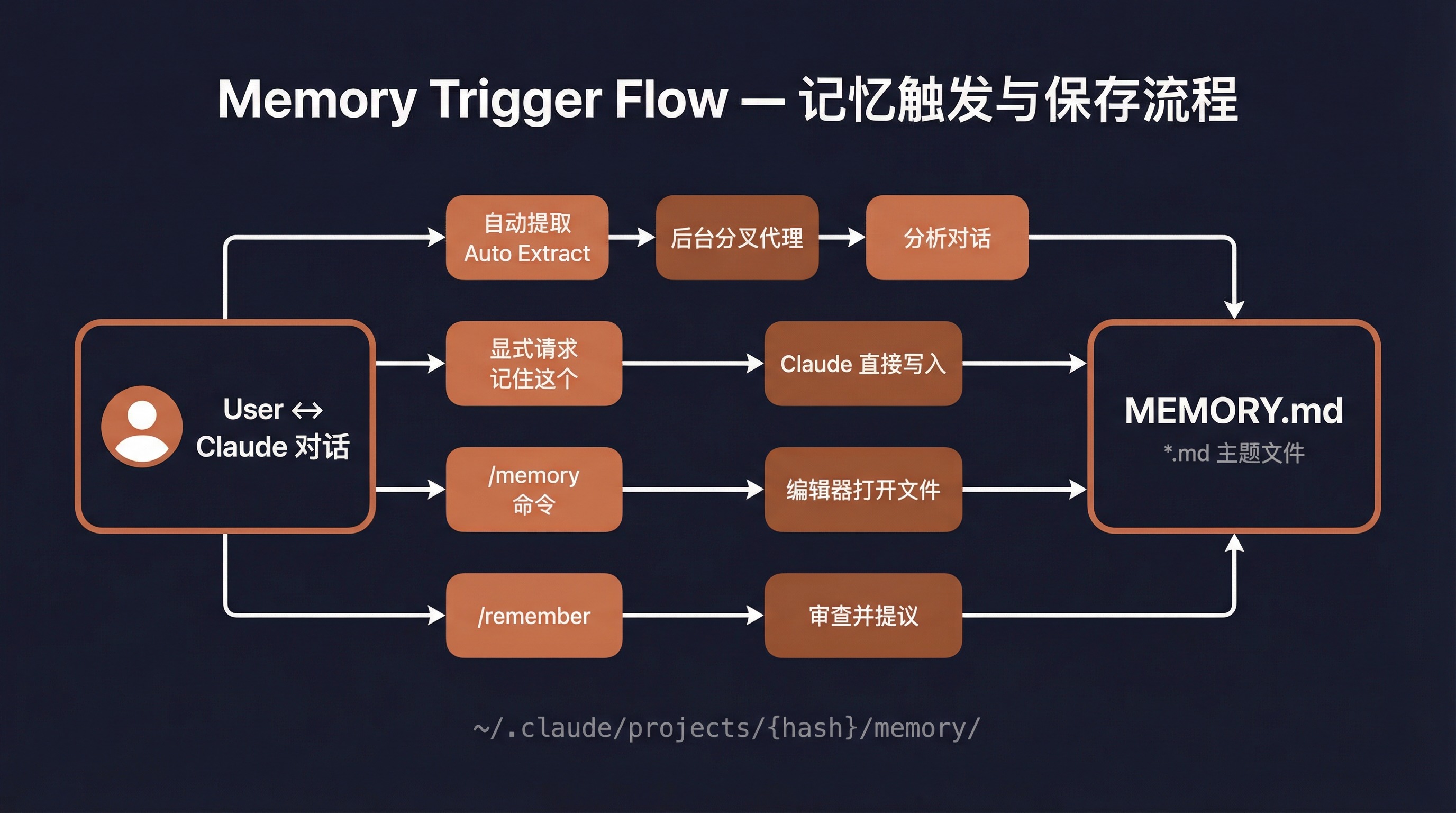
方式一:自动提取(最常用)
这是最主要的方式。你不需要做任何事情,Claude 会在每次对话结束时自动分析对话内容,提取值得记住的信息。
工作流程:
- 你和 Claude 正常对话
- Claude 完成回复(没有工具调用时)
- 后台启动一个记忆提取子代理
- 子代理分析最近的对话内容
- 识别出值得保存的记忆
- 写入记忆文件 + 更新 MEMORY.md 索引
终端会显示通知:
Memory updated in ~/.claude/projects/.../memory/feedback_testing.md · /memory to edit方式二:显式要求
直接告诉 Claude "记住这个":
用户:记住,这个项目部署前必须运行 bun test
Claude:[立即保存为 feedback 类型记忆]方式三:/memory 命令
在终端输入 /memory 命令,会打开一个文件选择器,让你在编辑器中直接编辑记忆文件。
> /memory这会列出所有可编辑的记忆文件(CLAUDE.md、CLAUDE.local.md、auto-memory 等),选择后用你的 $EDITOR 或 $VISUAL 打开。
方式四:/remember 命令
输入 /remember 触发记忆审查技能,它会:
- 审查所有自动记忆条目
- 提议将合适的条目提升到 CLAUDE.md 或 CLAUDE.local.md
- 检测重复、过时和冲突的记忆
- 不会直接修改,所有变更需要你批准
四、记忆存储在哪里?
目录结构
~/.claude/
└── projects/
└── {项目路径哈希}/
└── memory/ ← 自动记忆目录
├── MEMORY.md ← 索引文件(始终加载到上下文)
├── user_role.md ← 用户画像记忆
├── feedback_testing.md ← 行为反馈记忆
├── project_freeze.md ← 项目动态记忆
├── reference_linear.md ← 外部引用记忆
└── team/ ← 团队共享记忆(如启用)
├── MEMORY.md
└── ...记忆文件格式
每个记忆文件使用 YAML frontmatter + Markdown 内容:
---
name: 测试策略偏好
description: 集成测试必须使用真实数据库,不要 mock
type: feedback
---
集成测试必须使用真实数据库,不要 mock。
**Why:** 上季度 mock 测试通过但生产环境迁移失败,mock/生产差异掩盖了问题。
**How to apply:** 编写或审查测试时,确保数据库操作使用真实连接。MEMORY.md 索引文件
MEMORY.md 是索引而不是内容。它始终加载到上下文中,每行一个条目:
- [用户角色](user_role.md) — 数据科学家,关注可观测性/日志
- [测试策略](feedback_testing.md) — 集成测试用真实数据库,不 mock
- [合并冻结](project_freeze.md) — 2026-03-05 起冻结非关键合并
- [Bug 追踪](reference_linear.md) — 流水线 bug 在 Linear INGEST 项目限制:最多 200 行或 25KB,超出会被截断。
五、如何管理记忆
让 Claude 遗忘
用户:忘记关于合并冻结的记忆
Claude:[找到并删除相关记忆文件和索引条目]让 Claude 忽略记忆
用户:忽略记忆,从零开始
Claude:[本次对话中不使用任何记忆内容]手动编辑
直接编辑 ~/.claude/projects/{hash}/memory/ 下的文件,或使用 /memory 命令。
禁用自动记忆
| 方法 | 做法 |
|---|---|
| 环境变量 | CLAUDE_CODE_DISABLE_AUTO_MEMORY=1 |
| 设置文件 | settings.json 中 "autoMemoryEnabled": false |
| 精简模式 | --bare 启动 / CLAUDE_CODE_SIMPLE=1 |
自定义记忆目录
在 ~/.claude/settings.json 中设置:
{
"autoMemoryDirectory": "~/my-claude-memories"
}支持 ~/ 展开。出于安全考虑,项目级 .claude/settings.json 不允许设置此项。
六、记忆的生命周期
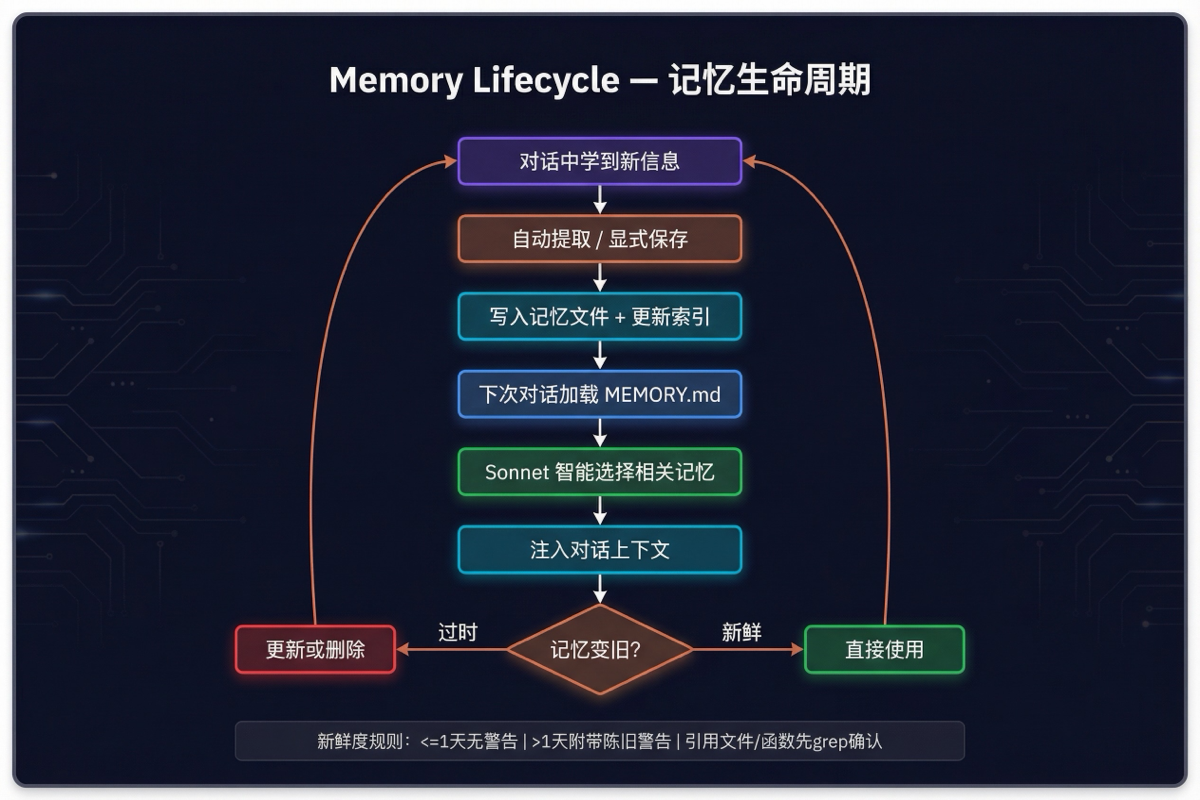
对话中学到新信息
↓
自动提取 / 显式保存
↓
写入记忆文件 + 索引
↓
下次对话加载 MEMORY.md
↓
智能选择相关记忆(Sonnet)
↓
注入到对话上下文
↓
记忆变旧?验证后再使用
↓
过时?更新或删除
↓
(24h + 5个会话后)
↓
AutoDream 后台整合记忆AutoDream —— "做梦"整理记忆
Claude Code 有一个隐藏的 AutoDream 功能,类比人类睡眠时大脑整理记忆的过程。当满足以下条件时,Claude 会在后台静默启动一个"做梦"子智能体:
- 距上次整合 >= 24 小时
- 期间积累了 >= 5 个会话
做梦过程分四阶段:定向 → 收集 → 整合 → 修剪。底部状态栏会显示 "dreaming",你可以按 Shift+Down 查看进度,按 x 终止。
详细技术分析见 AutoDream 记忆整合。
新鲜度管理
- 今天/昨天的记忆:直接使用
- 超过 1 天的记忆:附带陈旧警告,提醒 Claude 验证后再引用
- 引用文件路径/函数名的记忆:使用前先 grep 确认还存在
七、快速参考
| 操作 | 方法 |
|---|---|
| 让 Claude 记住 | "记住:这个项目用 bun 不用 npm" |
| 让 Claude 忘记 | "忘记关于 XXX 的记忆" |
| 编辑记忆 | /memory 命令 |
| 审查和整理 | /remember 命令 |
| 忽略记忆 | "忽略记忆" / "不要用记忆" |
| 禁用自动记忆 | CLAUDE_CODE_DISABLE_AUTO_MEMORY=1 |
| 禁用 AutoDream | settings.json 中 "autoDreamEnabled": false |
| 手动整合记忆 | /dream 命令 |
| 查看记忆目录 | ~/.claude/projects/{hash}/memory/ |