Claude Code Agent 框架深度解析
从源码视角剖析全球最流行 AI Code Editor 背后的 Agent 架构设计哲学。
核心循环 · 提示词工程 · 工具系统 · 上下文管理 · 技能与插件 · 权限与安全 · 故障恢复 · 对比分析 · 成功之道
导读:一个根本性的问题
如果你仔细观察 Claude Code 的行为,会发现一些非常有趣的现象:
- 它能在一次对话中修改几十个文件,且极少出错
- 它能自动恢复各种边界情况(token 溢出、API 超时、工具失败)
- 它能同时管理多个子代理协作完成复杂任务
- 长对话不会退化,反而能越来越精准
这些能力的背后,是一套精心设计的 Agent 框架。本文从源码层面,完整解构这套框架的设计哲学。
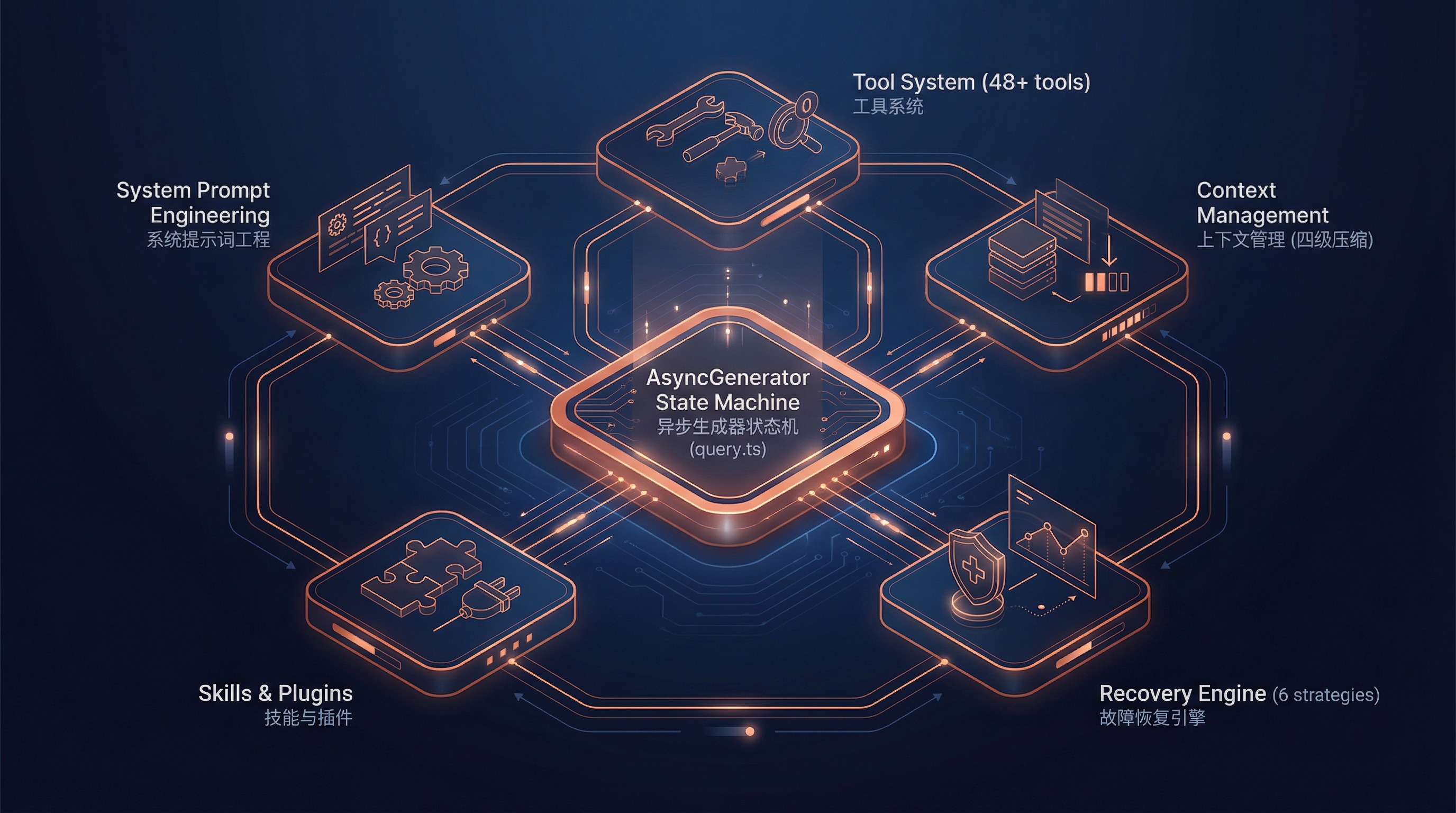
一、核心 Agent 循环
1.1 不是 ReAct,而是 Async Generator 状态机
大多数 Agent 框架(包括 LangChain)采用经典的 ReAct 模式:
思考(Thought) → 行动(Action) → 观察(Observation) → 思考 → ...Claude Code 没有采用这个模式。它的核心是一个 异步生成器(Async Generator)驱动的状态机,定义在 src/query.ts(约 1730 行):
// src/query.ts:219
export async function* query(params: QueryParams): AsyncGenerator<...>这个函数是整个 Agent 的心脏。它不是简单的"想-做-看"循环,而是一个流式状态机,通过 yield 实时产出消息,通过状态赋值(而非递归调用)驱动循环。
1.2 状态结构
// src/query.ts:204-217
type State = {
messages: Message[] // 完整对话历史
toolUseContext: ToolUseContext // 工具执行上下文
autoCompactTracking: AutoCompactTracking // 自动压缩追踪
maxOutputTokensRecoveryCount: number // 输出恢复计数
hasAttemptedReactiveCompact: boolean // 是否已尝试反应式压缩
maxOutputTokensOverride: number // 输出 token 覆盖值
pendingToolUseSummary: Promise<...> // 待处理的工具摘要
stopHookActive: boolean // 停止钩子状态
turnCount: number // 对话轮数
transition: Continue | undefined // 状态转换原因
}1.3 核心循环的五个阶段
整个 while (true) 循环(src/query.ts:307-1728)分为五个阶段:
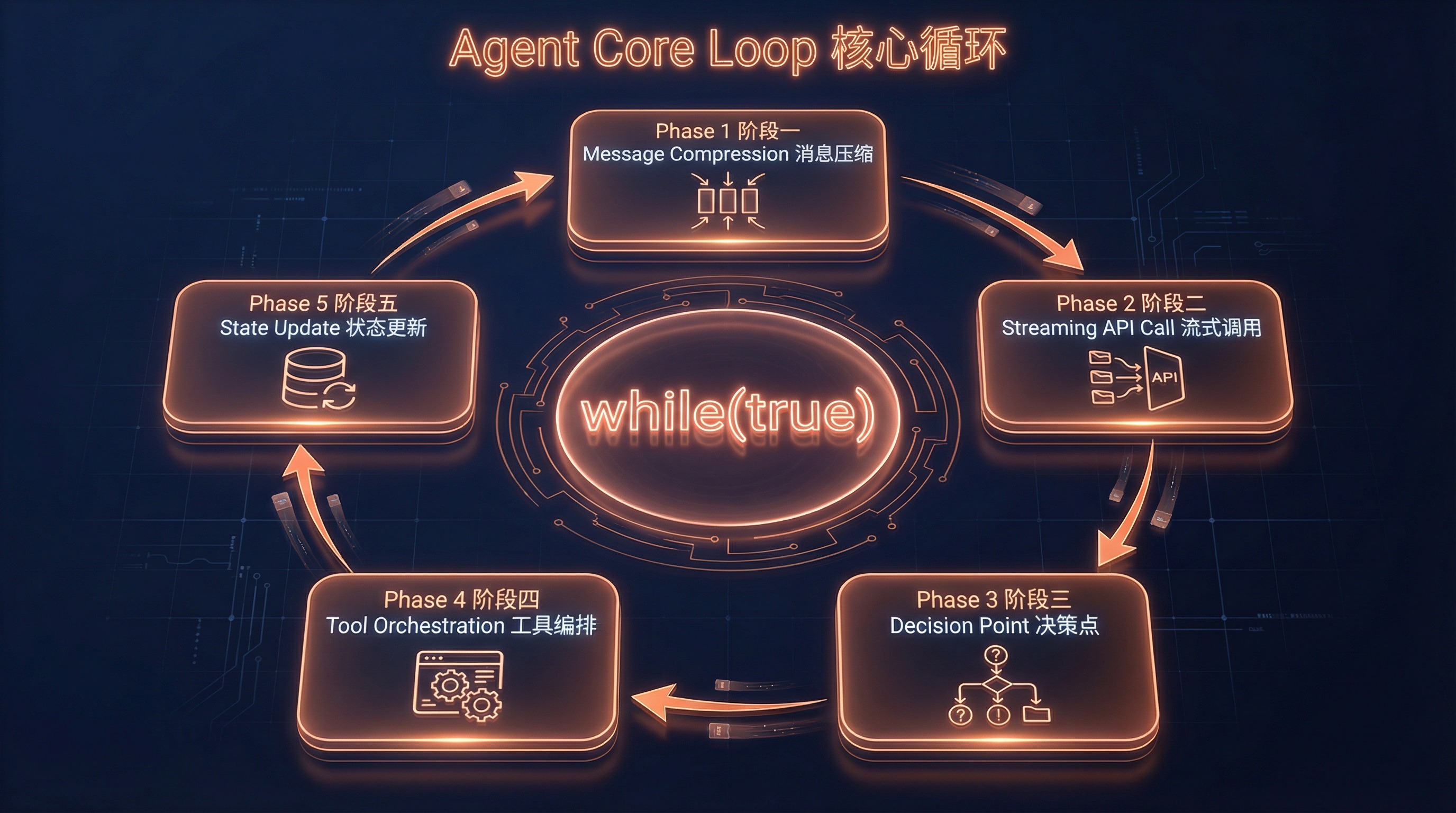
阶段 1:消息准备与智能压缩(第 365-543 行)
在调用 API 之前,对话历史会经过四层压缩处理:
| 压缩策略 | 原理 | 触发时机 |
|---|---|---|
| Snip 压缩 | 智能删除旧消息中的冗余 token | 每轮自动 |
| Micro 压缩 | 修改已缓存消息的内容 | 每轮自动 |
| 上下文折叠 | 分阶段摘要历史消息 | 上下文接近限制时 |
| Auto Compact | 通过 Claude 生成完整摘要 | 上下文严重不足时 |
这是 Claude Code 能处理极长对话而不退化的关键——它不会简单地截断历史,而是智能地压缩和保留关键信息。
阶段 2:流式 API 调用(第 652-954 行)
// src/query.ts:659-708
for await (const message of deps.callModel({
messages: prependUserContext(messagesForQuery, userContext),
systemPrompt: fullSystemPrompt,
thinkingConfig,
tools: toolUseContext.options.tools,
signal: abortController.signal,
}))关键设计:工具在流式传输过程中就开始执行,而不是等模型生成完整响应。这通过 StreamingToolExecutor 实现——当模型生成 tool_use 块时,工具立即开始运行。
阶段 3:决策点(第 1062-1358 行)
模型响应完成
│
├─ 有工具调用? ──→ 继续循环(阶段 4)
│
└─ 无工具调用? ──→ 运行 Stop 钩子 → 检查 token 预算 → 返回结果阶段 4:工具编排执行(第 1363-1409 行)
工具执行不是简单的逐个运行,而是有精心设计的编排策略(src/services/tools/toolOrchestration.ts):
工具调用列表
│
├─ 分区:只读 vs 写入
│
├─ 只读工具 ──→ 并行执行(最多 10 个并发)
│
└─ 写入工具 ──→ 串行执行(防止竞态条件)阶段 5:状态更新与循环(第 1704-1728 行)
这是整个设计最优雅的部分——通过状态赋值而非递归调用驱动循环:
// src/query.ts:1715-1728
const next: State = {
messages: [...messagesForQuery, ...assistantMessages, ...toolResults],
toolUseContext: toolUseContextWithQueryTracking,
autoCompactTracking: tracking,
turnCount: nextTurnCount,
transition: { reason: 'next_turn' },
}
state = next
// 回到 while(true) 循环顶部没有递归,没有回调地狱,只是简单的 state = next 然后 continue。这保证了:
- 内存稳定:不会因为深度递归导致栈溢出
- 状态可追溯:每一轮的状态转换原因都被记录
- 恢复可控:任何阶段的错误都可以通过修改 state 来恢复
二、系统提示词工程
2.1 分层构建架构
系统提示词不是一个静态字符串,而是通过分层管道动态组装的(src/constants/prompts.ts:444-577):
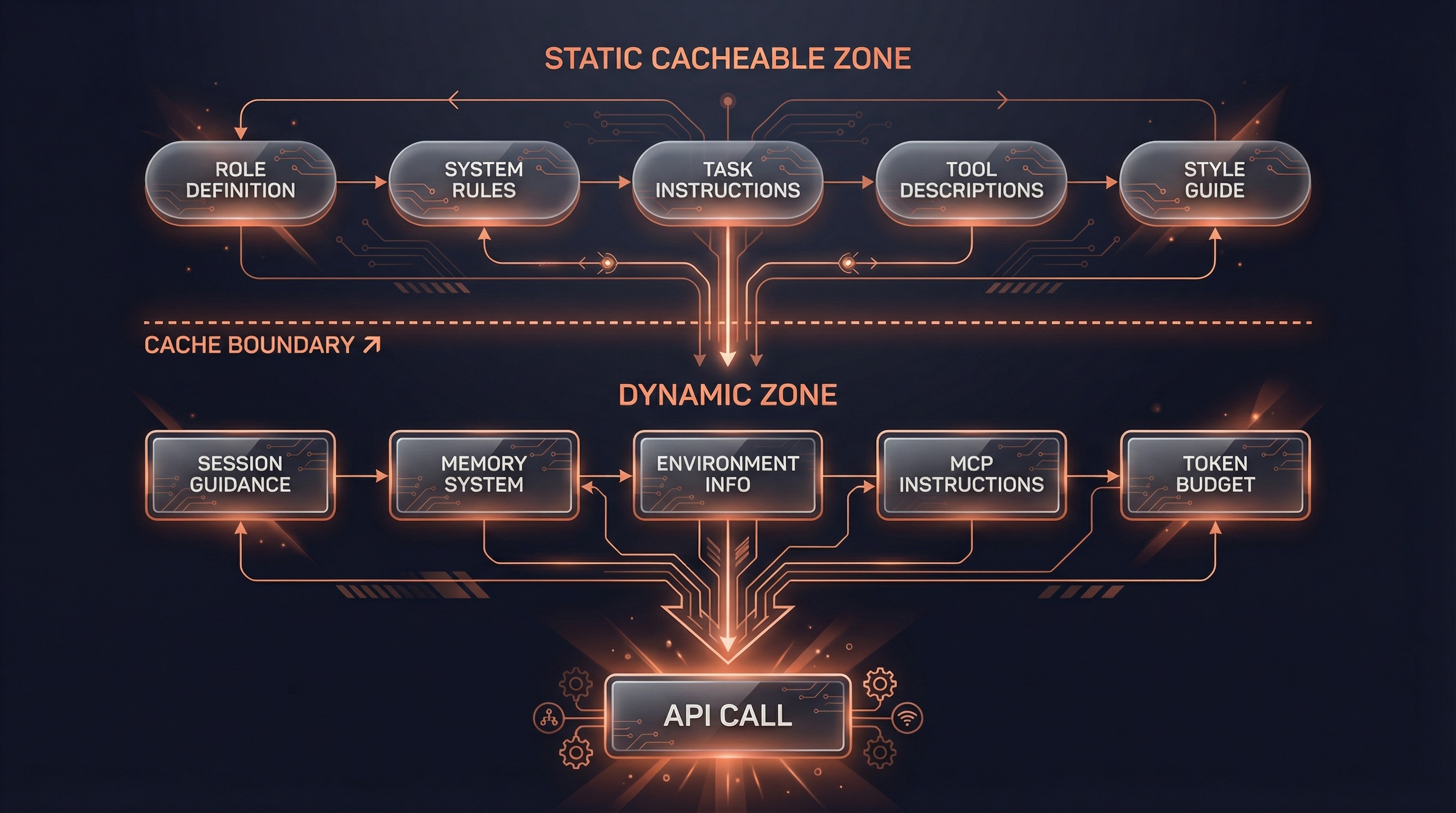
┌─────────────────────────────────────────────────────────────┐
│ 静态可缓存区域 │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ 角色定义 │ 系统规则 │ 任务指导 │ 工具说明 │ 风格 │ │
│ └───────────────────────────────────────────────────────┘ │
├─────────────────────── 缓存边界 ────────────────────────────┤
│ 动态可变区域 │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ 会话指引 │ 记忆系统 │ 环境信息 │ MCP 指令 │ Token 预算 │ │
│ └───────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘这里的**缓存边界(SYSTEM_PROMPT_DYNAMIC_BOUNDARY)**是一个关键设计:
- 边界之上:跨用户、跨组织通用的内容,使用
scope: 'global'缓存 - 边界之下:用户/会话特定的内容,使用
scope: 'ephemeral'缓存
这意味着 Claude Code 的系统提示词不需要每次都重新处理——静态部分在全球范围内共享缓存,大幅降低延迟和成本。
2.2 两种 Section 类型
// src/constants/systemPromptSections.ts
// 类型 1:缓存 Section(计算一次,整个会话复用)
systemPromptSection('memory', async () => {
return buildMemoryLines() // 读取 CLAUDE.md、记忆文件等
})
// 类型 2:缓存破坏 Section(每轮重新计算)
DANGEROUS_uncachedSystemPromptSection('mcp_instructions', async () => {
return getMcpInstructions() // MCP 服务器可能中途连接/断开
}, 'MCP servers can connect/disconnect mid-session')2.3 CLAUDE.md 的加载机制
CLAUDE.md 是用户自定义指令系统,按优先级从低到高加载(src/utils/claudemd.ts):
/etc/claude-code/CLAUDE.md ← 全局管理配置(最低优先级)
↓
~/.claude/CLAUDE.md ← 用户全局指令
↓
项目根目录/CLAUDE.md ← 项目级指令
项目根目录/.claude/CLAUDE.md
项目根目录/.claude/rules/*.md
↓
项目根目录/CLAUDE.local.md ← 本地私有指令(最高优先级)支持 @path 语法递归引用其他文件,并自动防止循环引用。
2.4 系统提示词的优先级解析
最终的系统提示词通过 buildEffectiveSystemPrompt()(src/utils/systemPrompt.ts:41-123)按优先级决定:
- Override 提示词 — 完全替换(Loop 模式使用)
- Coordinator 提示词 — 协调者模式
- Agent 提示词 — 自定义 Agent 定义
- Custom 提示词 —
--system-prompt命令行参数 - 默认提示词 — 标准系统提示词
- Append 提示词 — 始终追加到末尾
三、工具系统设计
3.1 工具接口:不只是函数调用
Claude Code 的工具不是简单的"名称 + 参数 + 执行"。每个工具是一个完整的生命周期管理单元(src/Tool.ts:362-695):
type Tool<Input, Output> = {
// 身份
name: string
aliases?: string[] // 向后兼容的旧名称
searchHint?: string // ToolSearch 关键词匹配
// 能力声明
isEnabled(): boolean
isConcurrencySafe(input): boolean // 是否可并行
isReadOnly(input): boolean // 是否只读
isDestructive(input): boolean // 是否破坏性
// 生命周期
validateInput(input, context) // 输入验证
checkPermissions(input, context) // 权限检查
call(input, context, ...) // 实际执行
// 输出与渲染
renderToolUseMessage(input) // 渲染调用信息
renderToolResultMessage(content) // 渲染结果信息
renderToolUseProgressMessage(...) // 渲染进度
mapToolResultToToolResultBlockParam() // 映射为 API 格式
// 智能特性
inputSchema: Zod schema // Zod 类型验证
maxResultSizeChars: number // 结果大小阈值
toAutoClassifierInput(input) // 安全分类器输入
getToolUseSummary?(input): string // 工具使用摘要
}这种设计使得每个工具都是自描述、自验证、自渲染的——框架不需要了解工具的内部逻辑,只需调用标准接口。
3.2 工具注册:三阶段流水线
工具的发现和注册分三个阶段(src/tools.ts):
阶段 1:基础工具池(getAllBaseTools)
│ ~48 个内置工具
│ + Feature Flag 控制的条件工具
│
阶段 2:过滤(getTools)
│ 按权限模式过滤
│ 按 REPL 模式过滤
│ 按 isEnabled() 过滤
│
阶段 3:MCP 合并(assembleToolPool)
+ MCP 服务器提供的动态工具
去重(内置优先)
排序(缓存稳定性)3.3 工具执行管道
一次工具调用要经过7 步管道(src/services/tools/toolExecution.ts):
1. 工具查找 ─→ 2. 输入解析(Zod) ─→ 3. 自定义验证
│
4. Pre-Tool 钩子 ─→ 5. 权限检查 ─→ 6. 实际执行 ─→ 7. Post-Tool 钩子每一步都可以中断、修改或增强执行流程。这不是简单的 try { tool.call(input) } catch,而是一个完整的中间件管道。
3.4 工具延迟加载(Tool Deferred Loading)
Claude Code 有 48+ 个内置工具。如果每次 API 调用都把所有工具定义发给模型,会浪费大量 token。解决方案:
// 工具可以标记为"延迟加载"
{
shouldDefer: true, // 只在 ToolSearch 中列出名称
alwaysLoad: false, // 不在初始提示词中包含完整 schema
searchHint: "notebook" // 搜索关键词
}模型需要时通过 ToolSearch 工具动态获取完整定义。这大幅减少了系统提示词的大小。
四、上下文管理与压缩
4.1 无限对话的秘密
Claude Code 宣称"对话没有上下文限制",这背后是一套四级压缩系统:
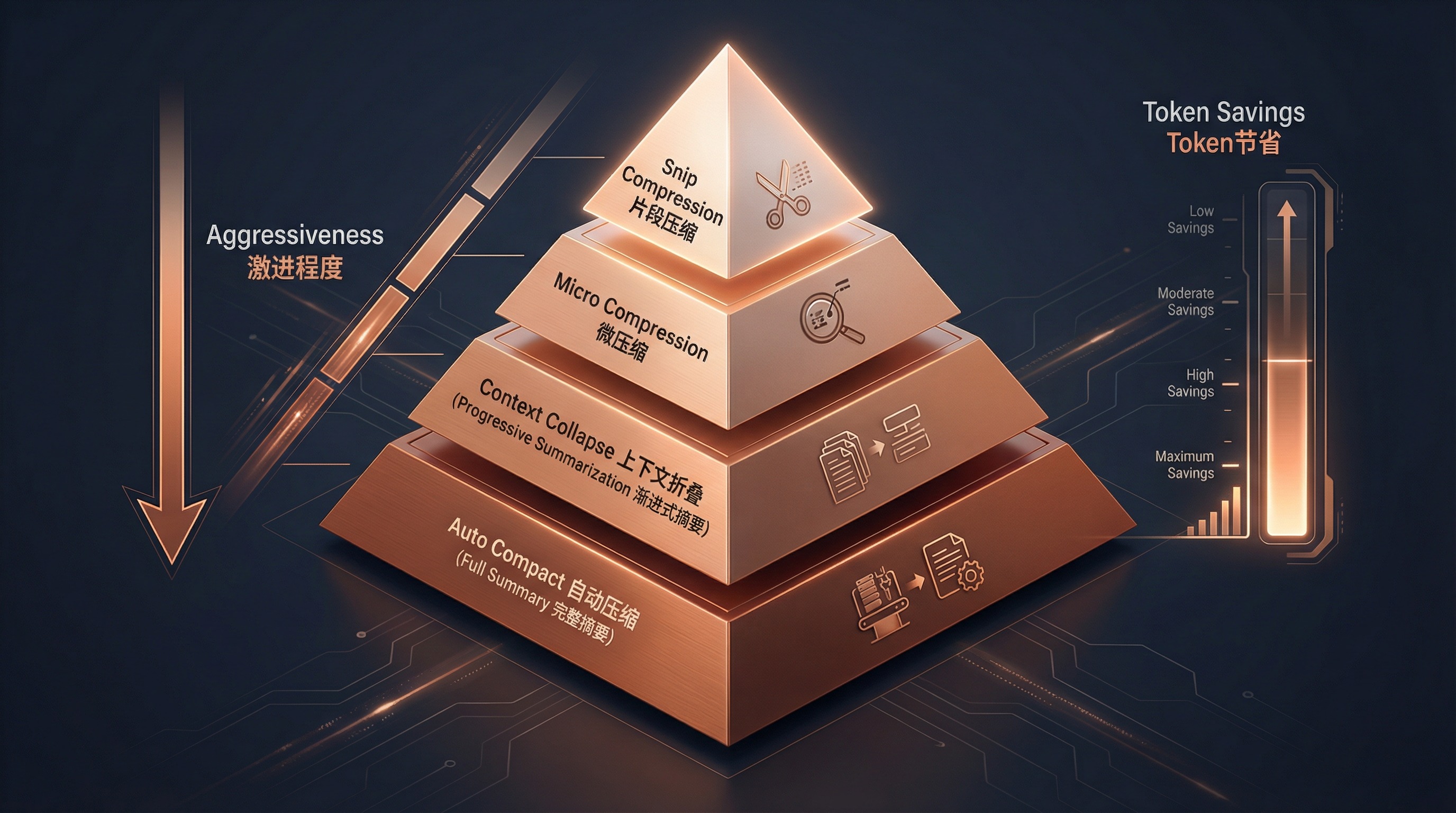
第 1 级:Snip 压缩
对已处理的消息进行智能裁剪——移除重复的文件内容、过长的工具输出等。
第 2 级:Micro 压缩
修改已缓存消息的内容,而不改变缓存键。这是一种"原地优化"策略。
第 3 级:上下文折叠(Context Collapse)
将历史消息分阶段摘要。不是一次性摘要全部,而是渐进式折叠——先摘要最旧的消息,保留最近的细节。
第 4 级:Auto Compact
当所有局部优化都不够时,通过 Claude 自身生成一个完整的对话摘要,替换所有历史消息。
4.2 系统上下文注入
每次 API 调用前,自动注入两种上下文(src/context.ts):
// 系统上下文(memoized,整个会话缓存)
getSystemContext() → {
gitStatus, // 当前分支、最近提交、文件状态
cacheBreakerInjection // 系统级注入
}
// 用户上下文(memoized,CLAUDE.md 变化时清除)
getUserContext() → {
claudeMdContent, // 所有 CLAUDE.md 合并内容
currentDate, // 当前日期
mcpInstructions // MCP 服务器指令
}4.3 系统提醒(System Reminders)
系统提醒是一种特殊的附件消息,注入到工具结果或用户消息中(src/utils/attachments.ts):
<system-reminder>
这里是系统级的上下文信息,与具体的工具结果无关。
</system-reminder>用途包括:
- 文件读取时的安全警告
- 记忆系统的时效提醒
- 用户侧问的附带信息
- Deferred 工具的可用通知
五、技能与插件生态
5.1 技能系统(Skills)
技能是 Claude Code 最强大的扩展机制之一。它不是简单的"命令别名",而是完整的 AI 行为定义。
技能定义结构
type BundledSkillDefinition = {
name: string
description: string
whenToUse?: string // 模型自动判断何时使用
allowedTools?: string[] // 限制工具池
model?: string // 指定模型
hooks?: HooksSettings // 生命周期钩子
context?: 'inline' | 'fork' // 内联 or 独立上下文
agent?: string // 关联的 Agent 类型
getPromptForCommand: (args, context) => Promise<ContentBlockParam[]>
}两种执行上下文
| 上下文 | 行为 | 适用场景 |
|---|---|---|
inline | 技能内容直接展开到当前对话 | 简单指令、格式模板 |
fork | 技能作为子代理在独立上下文中运行 | 复杂工作流、需要独立 token 预算 |
技能发现来源
内置技能(bundled) ← 编译到 CLI 中,15+ 个
↓
插件技能(plugin) ← 插件注册
↓
用户技能(~/.claude/skills/) ← 用户全局
↓
项目技能(.claude/skills/) ← 项目级
↓
策略技能(policy) ← 组织管理5.2 插件系统(Plugins)
插件是更高层级的扩展单元,可以包含技能、钩子、MCP 服务器、LSP 服务器:
type BuiltinPluginDefinition = {
name: string
description: string
skills?: BundledSkillDefinition[] // 技能集合
hooks?: HooksSettings // 生命周期钩子
mcpServers?: Record<string, McpServerConfig> // MCP 服务器
lspServers?: Record<string, LspServerConfig> // LSP 服务器
isAvailable?: () => boolean // 可用性检查
defaultEnabled?: boolean // 默认启用
}插件的关键设计:用户可切换启用/禁用,这与直接注册的技能不同。
5.3 钩子系统(Hooks)
钩子是整个生命周期的可编程拦截点:
SessionStart ─→ UserPromptSubmit ─→ PreToolUse ─→ [工具执行]
│ │
│ PostToolUse
│ │
└─ SubagentStart ←─── Stop ←─── TaskCompleted ←┘
│
SubagentStop ─→ SessionEnd钩子通过 shell 命令执行,退出码控制行为:
- 0:成功,stdout 内容按事件类型处理
- 2:stderr 内容展示给模型或用户
- 其他:仅展示给用户
5.4 MCP:模型上下文协议
MCP 是 Claude Code 与外部世界交互的标准协议。工具命名规范:
mcp__{标准化服务器名}__{工具名}
例如:mcp__chrome_devtools__take_screenshot支持的传输方式:stdio、sse、http、websocket、sdk
MCP 工具在运行时动态发现,与内置工具无缝合并到统一的工具池中。
六、权限与安全体系
6.1 分层权限模型
┌─────────────────────────────────────┐
│ 权限规则(Rules) │
│ 来源:userSettings, projectSettings │
│ flagSettings, policySettings │
├─────────────────────────────────────┤
│ 权限模式(Modes) │
│ default | plan | acceptEdits │
│ bypassPermissions | auto | bubble │
├─────────────────────────────────────┤
│ 钩子(Hooks) │
│ PreToolUse 可拦截或修改 │
├─────────────────────────────────────┤
│ 安全分类器(Classifier) │
│ ML 模型评估工具调用安全性 │
└─────────────────────────────────────┘6.2 权限决策流
每次工具调用的权限检查:
type PermissionResult =
| { behavior: 'allow', updatedInput?, decisionReason }
| { behavior: 'ask', message, suggestions }
| { behavior: 'deny', message, decisionReason }
| { behavior: 'passthrough', message }决策原因追溯:
type: 'rule'— 匹配了权限规则type: 'mode'— 权限模式决定type: 'hook'— 钩子拦截type: 'classifier'— ML 分类器判定
6.3 权限规则模式匹配
// 精确匹配
{ tool: 'Bash', behavior: 'deny' }
// 参数模式匹配
{ tool: 'Bash(git *)', behavior: 'allow' } // 允许所有 git 命令
{ tool: 'Bash(rm -rf *)', behavior: 'deny' } // 禁止 rm -rf
// 通配符
{ tool: 'File*', behavior: 'allow' } // 允许所有 File 开头的工具七、故障恢复机制
这是 Claude Code 最精妙的设计之一。src/query.ts 的核心循环内置了6 种恢复策略:
| 恢复策略 | 触发条件 | 恢复方式 |
|---|---|---|
collapse_drain_retry | prompt 过长 | 排空已暂存的上下文折叠,重试 |
reactive_compact_retry | 仍然过长 | 通过 Claude 生成摘要,重试 |
max_output_tokens_escalate | 触及 8k 默认限制 | 升级到 64k 限制重试 |
max_output_tokens_recovery | 触及任何限制 | 注入"继续"提示,重试(最多 3 次) |
stop_hook_blocking | Stop 钩子阻塞 | 将阻塞错误注入上下文,重试 |
token_budget_continuation | 预算尚余 | 注入预算提示,继续执行 |
每种恢复都通过修改 state 实现:
// 例:prompt 过长恢复
if (error.type === 'prompt_too_long') {
// 排空所有暂存的折叠
const compacted = drainStagedCollapses(state.messages)
state = { ...state, messages: compacted, transition: { reason: 'collapse_drain_retry' } }
continue // 回到循环顶部重试
}7.1 模型降级
当主模型流式传输失败时,系统会:
- 清理孤立的未完成消息
- 切换到备用模型
- 用新模型重试
7.2 媒体大小恢复
当图片等媒体内容导致 token 超限时:
- 触发反应式压缩
- 自动剥离图片内容
- 保留文本信息重试
八、与 LangChain/ReAct 的本质区别
8.1 架构范式对比
| 维度 | LangChain | Claude Code |
|---|---|---|
| 核心模式 | ReAct(Think→Act→Observe) | Async Generator 状态机 |
| 执行模型 | 同步阻塞 | 流式非阻塞 |
| 工具执行 | 等待模型完整响应后执行 | 流式传输中即时执行 |
| 状态管理 | 外部 Memory 对象 | 内置状态赋值 + 循环 |
| 错误恢复 | 需要手动编排 | 6 种内置恢复策略 |
| 上下文压缩 | 简单截断或摘要 | 四级渐进式压缩 |
| 多 Agent | Chain/Graph 显式编排 | 统一工具接口 + 状态机 |
| 扩展机制 | Python 类继承 | 技能 + 插件 + 钩子 + MCP |
| 缓存策略 | 无 | 全局/会话/按轮三级缓存 |
8.2 为什么不用 ReAct?
ReAct 模式有几个固有限制:
- 串行瓶颈:每一步必须等待完整的"思考→行动→观察"循环
- 无流式能力:模型生成完整响应后才能开始执行工具
- 恢复困难:没有统一的状态表示,难以实现自动恢复
- 缓存不友好:每次循环的 prompt 结构变化大,难以利用缓存
Claude Code 的 Async Generator 模式解决了所有这些问题:
- 流式执行:工具在模型生成过程中就开始运行
- 状态可控:
State对象包含所有需要的信息,恢复只需修改状态 - 缓存优化:静态提示词全局缓存,动态部分最小化
- 并行能力:只读工具自动并行,写入工具串行保序
8.3 与 LangChain Agent 的具体差异
LangChain Agent:
agent = initialize_agent(tools, llm, agent="zero-shot-react-description")
result = agent.run("do something")
# 内部:LLM → parse → tool → LLM → parse → tool → ... → final answer
# 每一步都是独立的 LLM 调用
Claude Code Agent:
for await (const msg of query({ messages, tools, systemPrompt })) {
yield msg // 实时产出消息
// 内部:流式 LLM → 流式工具执行 → 状态更新 → 继续
// 单次 API 调用可以触发多个工具,工具在流式中执行
}关键差异:
- LangChain 的每一"步"是一次完整的 LLM 调用
- Claude Code 的每一"轮"可以包含多个工具调用,且工具在流式传输中执行
- LangChain 需要 OutputParser 解析模型输出中的工具调用
- Claude Code 直接使用 Anthropic API 的原生
tool_use能力,无需解析
8.4 与 LangGraph 的对比
LangGraph 是 LangChain 的升级版,引入了图结构:
| 维度 | LangGraph | Claude Code |
|---|---|---|
| 状态流转 | 显式图节点 + 边 | 隐式状态机(while + continue) |
| 可视化 | 可导出为图 | 状态转换原因可追溯 |
| 持久化 | Checkpoint + State | 文件系统 + 消息历史 |
| 人机交互 | interrupt_before/after | 权限系统 + 钩子 |
| 多 Agent | 需要显式编排 | AgentTool 统一接口 |
Claude Code 的优势在于简单性——不需要定义图结构,一个 while 循环就能处理所有情况。
九、为什么 Claude Code 能做到这么好?
从源码分析中,我们可以总结出以下核心设计原则:
9.1 流式优先(Streaming First)
整个架构围绕 AsyncGenerator 设计,一切都是流式的:
- 模型响应是流式的
- 工具在流式中执行
- 进度实时更新
- 压缩策略是渐进式的
这意味着用户永远不需要等待——看到模型在思考、工具在执行、结果在产出。
9.2 智能缓存(Intelligent Caching)
三级提示词缓存系统(src/services/api/claude.ts:3213-3237):
Global Cache(跨组织) ← 静态系统提示词
↓
Ephemeral Cache(会话级) ← 动态系统提示词
↓
Section Cache(轮级) ← systemPromptSection 记忆化这大幅降低了每次 API 调用的延迟和成本。
9.3 优雅降级(Graceful Degradation)
6 种恢复策略确保 Claude Code 几乎不会因为技术问题中断用户的工作流:
- Token 超限?自动压缩
- API 超时?自动重试
- 模型失败?降级到备用模型
- 工具失败?记录错误,继续对话
9.4 最小抽象原则(Minimal Abstraction)
与 LangChain 的"万物皆抽象"不同,Claude Code 的核心只有:
- 一个循环(
while (true)inquery()) - 一个状态(
State对象) - 一个接口(
Tool类型)
没有 Agent → AgentExecutor → Chain → Memory → Callback 的嵌套抽象层。这使得代码易于理解、调试和扩展。
9.5 原生 API 集成(Native API Integration)
Claude Code 直接使用 Anthropic API 的原生能力:
- 原生工具调用:无需 OutputParser,直接使用
tool_use块 - 原生流式传输:无需包装层,直接消费 SSE 流
- 原生缓存:利用 API 的 prompt caching 特性
- 原生思维链:直接使用 extended thinking
这避免了"框架税"——LangChain 等框架在 LLM 和开发者之间增加的抽象层。
9.6 工具驱动的 Agent(Tool-Driven Agent)
Claude Code 的哲学是:Agent 的能力等于其工具的能力。
- 子代理生成?是一个工具(
AgentTool) - 团队管理?是一个工具(
TeamCreate/SendMessage) - 文件编辑?是一个工具(
FileEdit) - 技能执行?是一个工具(
SkillTool)
这意味着所有能力都通过统一的工具接口暴露,模型通过自然语言推理来决定使用哪个工具。不需要显式的编排逻辑——模型本身就是编排器。
9.7 深度集成的开发体验
Claude Code 不是"通用 Agent + 代码插件",而是从底层为编码场景深度优化:
- Git 感知:自动注入 git 状态,理解分支、提交、diff
- 文件系统感知:理解项目结构,智能搜索文件
- Worktree 隔离:安全的实验性修改环境
- LSP 集成:语言服务器协议提供类型信息和诊断
- MCP 生态:通过标准协议连接各种外部工具
十、架构总结
核心组件关系
用户输入
│
▼
QueryEngine(src/QueryEngine.ts)
│
├─ 构建系统提示词(prompts.ts + context.ts + claudemd.ts)
├─ 组装工具池(tools.ts + MCP)
│
▼
query() 异步生成器循环(src/query.ts)
│
├─ 阶段1: 消息压缩(snip → micro → collapse → compact)
├─ 阶段2: 流式 API 调用(callModel + StreamingToolExecutor)
├─ 阶段3: 决策点(继续 or 完成)
├─ 阶段4: 工具编排(并行只读 + 串行写入)
└─ 阶段5: 状态更新(state = next → continue)
│
├─ 恢复策略(6种)
├─ 钩子系统(PreToolUse / PostToolUse / Stop / ...)
└─ 子代理生成(AgentTool → runAgent → 新的 query() 实例)
│
├─ 同步前台
├─ 异步后台(LocalAgentTask)
├─ Fork(继承上下文)
└─ Teammate(邮箱通信)一句话总结
Claude Code 的 Agent 框架是一个以 AsyncGenerator 为核心的流式状态机,通过统一的工具接口暴露所有能力,配合四级上下文压缩、三级提示词缓存、六种故障恢复策略,实现了一个无需显式编排即可自主完成复杂编程任务的 AI 系统。
十一、关键源文件索引
| 组件 | 文件路径 | 说明 |
|---|---|---|
| 核心循环 | src/query.ts | Agent 主循环(~1730 行) |
| 查询引擎 | src/QueryEngine.ts | 高层封装(~687 行) |
| 工具定义 | src/Tool.ts | Tool 类型系统(~792 行) |
| 工具注册 | src/tools.ts | 工具发现和注册(~389 行) |
| 工具执行 | src/services/tools/toolExecution.ts | 执行管道(~1500 行) |
| 工具编排 | src/services/tools/toolOrchestration.ts | 并行/串行策略 |
| 系统提示词 | src/constants/prompts.ts | 提示词组装(~577 行) |
| 提示词 Sections | src/constants/systemPromptSections.ts | 分段缓存 |
| 上下文管理 | src/context.ts | 系统/用户上下文 |
| CLAUDE.md | src/utils/claudemd.ts | 用户指令加载 |
| 记忆系统 | src/memdir/memdir.ts | 持久化记忆 |
| Agent 生成 | src/tools/AgentTool/AgentTool.tsx | Agent 工具入口 |
| Agent 运行 | src/tools/AgentTool/runAgent.ts | Agent 执行逻辑 |
| Fork 代理 | src/tools/AgentTool/forkSubagent.ts | Fork 缓存优化 |
| 团队管理 | src/utils/swarm/teamHelpers.ts | Teams 基础设施 |
| 邮箱通信 | src/utils/teammateMailbox.ts | 异步消息队列 |
| 技能系统 | src/skills/bundledSkills.ts | 技能注册与管理 |
| 插件系统 | src/plugins/builtinPlugins.ts | 插件框架 |
| 钩子系统 | src/utils/hooks/hooksConfigManager.ts | 钩子管理 |
| 权限系统 | src/utils/permissions/permissions.ts | 权限检查 |
| 状态管理 | src/state/AppStateStore.ts | 全局状态 |
| 成本追踪 | src/cost-tracker.ts | API 成本计算 |
| API 客户端 | src/services/api/claude.ts | Anthropic API 封装 |
| MCP 客户端 | src/services/mcp/client.ts | MCP 协议实现 |
| 协调者模式 | src/coordinator/coordinatorMode.ts | 多 Agent 编排 |
| 远程会话 | src/remote/RemoteSessionManager.ts | CCR 连接管理 |
| Bridge | src/bridge/bridgeMain.ts | 远程桥接 |
十二、进一步阅读
- 使用指南 — 面向用户的多 Agent 使用手册
- 实现原理 — 多 Agent 编排的技术细节
- Anthropic API 文档 — 原生 API 能力
- MCP 协议规范 — 模型上下文协议