Claude Code 记忆系统 — 实现原理
从系统提示词注入到后台自动提取,拆解记忆系统的每一个技术细节。
整体架构 · 路径解析 · 提示词注入 · 自动提取 · 智能检索 · 记忆扫描 · 代理记忆 · 团队同步 · 常量速查 · 数据流总览
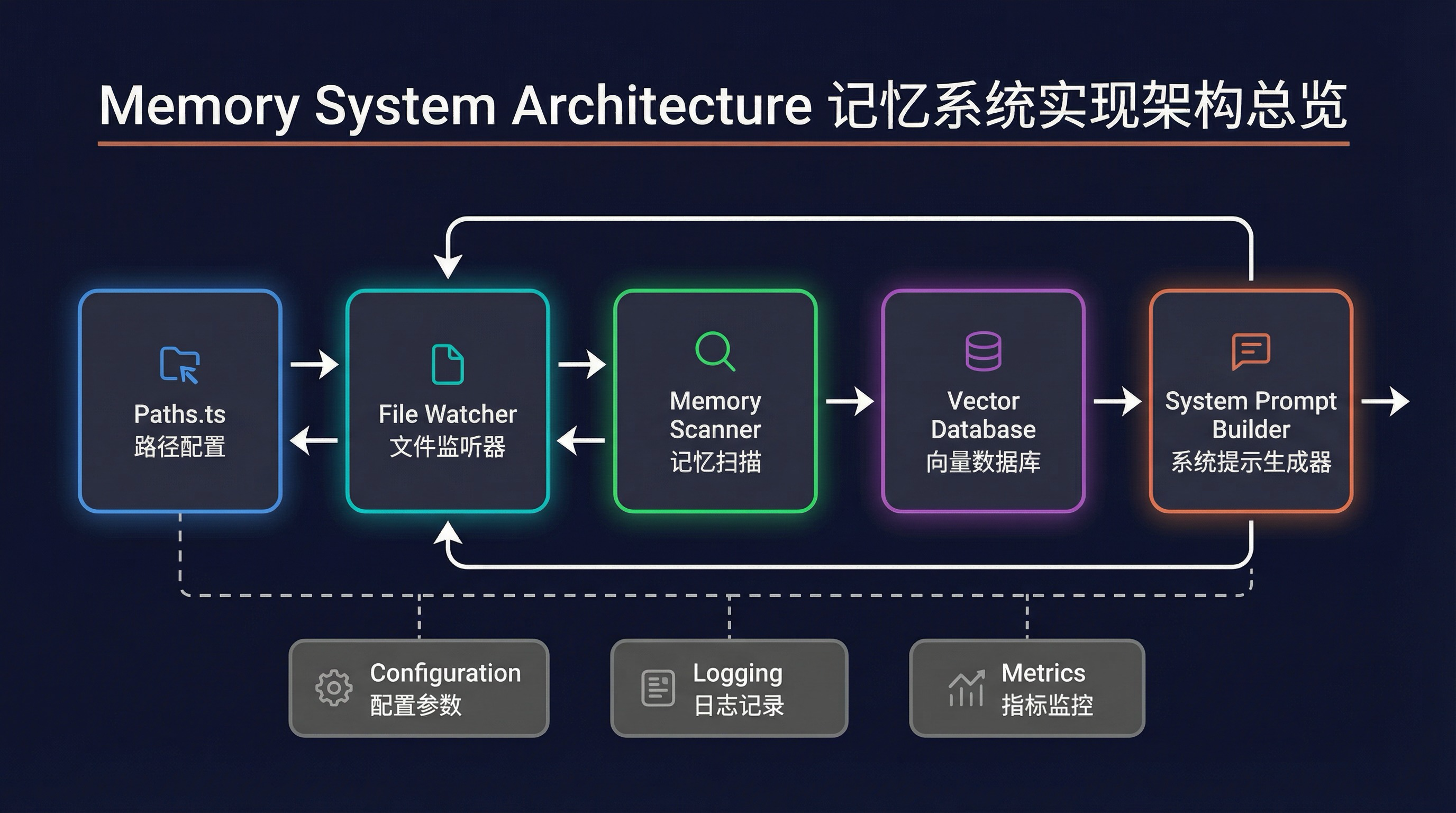
一、整体架构
记忆系统由 5 个核心模块协作完成:
| 模块 | 源码位置 | 职责 |
|---|---|---|
| 路径解析 | src/memdir/paths.ts | 计算记忆存储目录,处理覆盖和安全校验 |
| 提示词构建 | src/memdir/memdir.ts | 将记忆指令注入系统提示词 |
| 记忆扫描 | src/memdir/memoryScan.ts | 扫描目录、解析 frontmatter、排序 |
| 智能检索 | src/memdir/findRelevantMemories.ts | 用 Sonnet 选择与当前查询相关的记忆 |
| 自动提取 | src/services/extractMemories/ | 后台分叉代理,从对话中提取记忆 |
辅助模块:
| 模块 | 源码位置 | 职责 |
|---|---|---|
| AutoDream | src/services/autoDream/ | 后台记忆整合("做梦"),详见 03-autodream.md |
| 类型定义 | src/memdir/memoryTypes.ts | 四种记忆类型的分类法和提示词模板 |
| 新鲜度 | src/memdir/memoryAge.ts | 计算记忆年龄、生成陈旧警告 |
| 文件检测 | src/utils/memoryFileDetection.ts | 判断路径是否属于记忆系统 |
| 代理记忆 | src/tools/AgentTool/agentMemory.ts | 子代理专属的三级记忆目录 |
| 团队同步 | src/services/teamMemorySync/ | 记忆的远程上传/下载 |
二、路径解析系统

核心函数:getAutoMemPath()
路径解析优先级(从高到低):
1. CLAUDE_COWORK_MEMORY_PATH_OVERRIDE ← Cowork 环境变量(完整路径)
2. settings.json → autoMemoryDirectory ← 用户设置(支持 ~/ 展开)
3. {memoryBase}/projects/{sanitized-git-root}/memory/ ← 默认计算路径关键源码 src/memdir/paths.ts:223:
export const getAutoMemPath = memoize(
(): string => {
const override = getAutoMemPathOverride() ?? getAutoMemPathSetting()
if (override) return override
const projectsDir = join(getMemoryBaseDir(), 'projects')
return join(projectsDir, sanitizePath(getAutoMemBase()), AUTO_MEM_DIRNAME) + sep
},
() => getProjectRoot(), // 缓存 key = 项目根目录
)路径安全校验
validateMemoryPath() 拒绝危险路径:
| 被拒路径 | 原因 |
|---|---|
../foo | 相对路径,CWD 相关 |
/ 或 /a | 根路径或过短路径 |
C:\ | Windows 驱动器根目录 |
\\server\share | UNC 网络路径 |
含 \0 | 空字节,可在系统调用中截断 |
安全限制:项目级 .claude/settings.json 不允许设置 autoMemoryDirectory,防止恶意仓库通过此项获取对 ~/.ssh 等敏感目录的写权限。
启用条件
isAutoMemoryEnabled() 的判断链:
CLAUDE_CODE_DISABLE_AUTO_MEMORY=1 → 关闭
CLAUDE_CODE_SIMPLE (--bare) → 关闭
远程模式 且 无 REMOTE_MEMORY_DIR → 关闭
settings.json autoMemoryEnabled → 跟随设置
默认 → 开启三、系统提示词注入
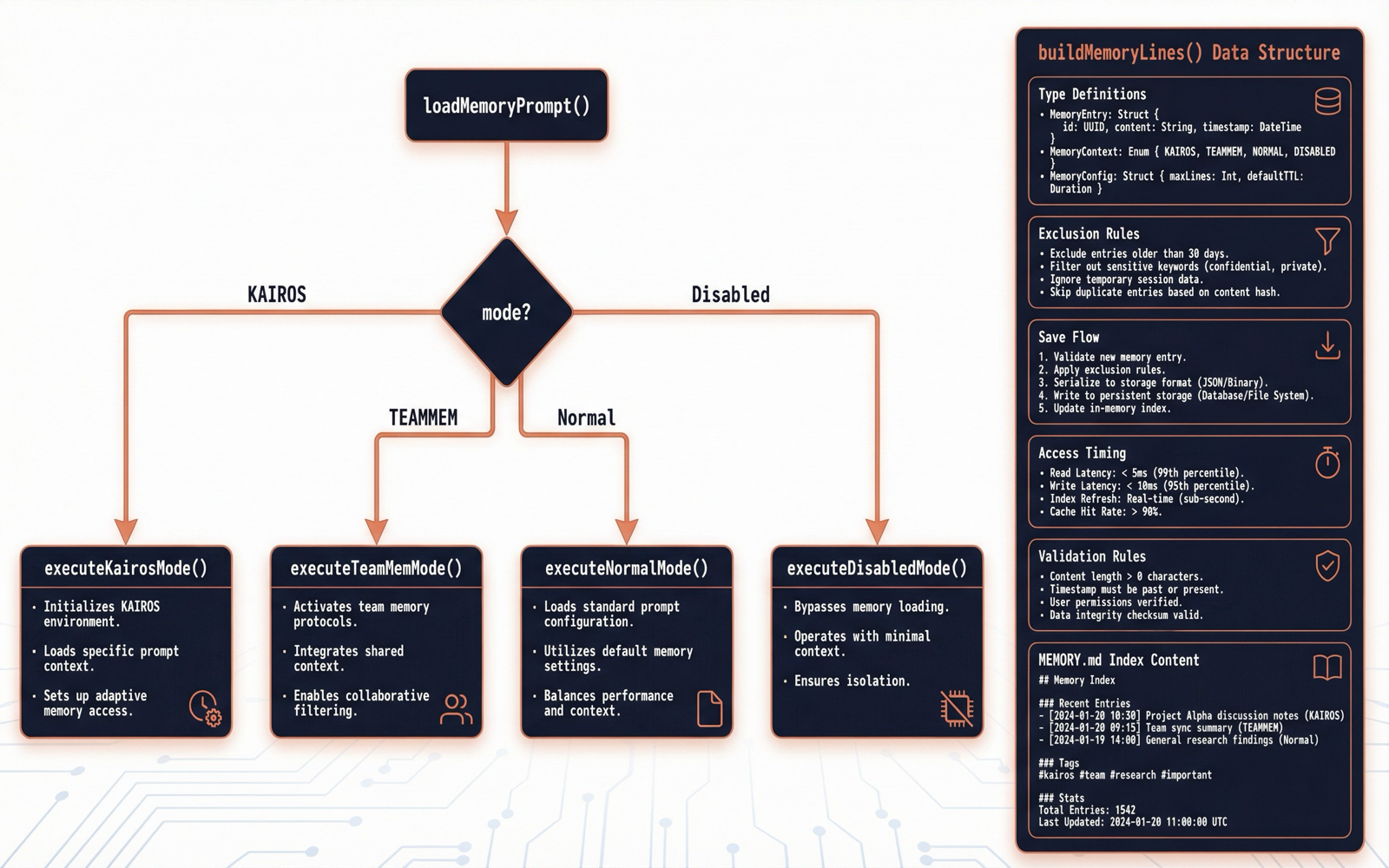
入口:loadMemoryPrompt()
这是记忆系统与系统提示词的接口。启动时调用一次(通过 systemPromptSection 缓存)。
loadMemoryPrompt()
├─ KAIROS 模式?→ buildAssistantDailyLogPrompt() [日志追加模式]
├─ TEAMMEM 开启?→ buildCombinedMemoryPrompt() [个人+团队双目录]
├─ 正常模式 → buildMemoryLines() [单目录]
└─ 禁用 → return nullbuildMemoryLines() 构建的提示词结构
# auto memory
你有一个持久化的文件记忆系统,位于 `{memoryDir}`...
## Types of memory ← 四种类型的定义和示例
## What NOT to save ← 排除规则
## How to save memories ← 两步保存流程
## When to access memories ← 何时查阅
## Before recommending ← 引用前验证
## Memory and other forms ← 与 Plan/Task 的区别
## MEMORY.md ← 索引内容(或"当前为空")MEMORY.md 截断策略
truncateEntrypointContent() 执行双重限制:
// 先截断行数
if (lineCount > 200) → 截断到 200 行
// 再截断字节数(处理超长行)
if (bytes > 25,000) → 在最后一个换行符处截断
// 附加警告
"WARNING: MEMORY.md is {reason}. Only part of it was loaded."目录自动创建
ensureMemoryDirExists() 在加载提示词时确保目录存在:
- 递归创建
mkdir(处理整个父链) - 吞掉
EEXIST(幂等) - 真正的权限错误只记日志不中断(Write 工具会显示真实错误)
提示词中明确告知模型目录已存在,避免浪费 turn 执行 ls 或 mkdir。
四、自动记忆提取
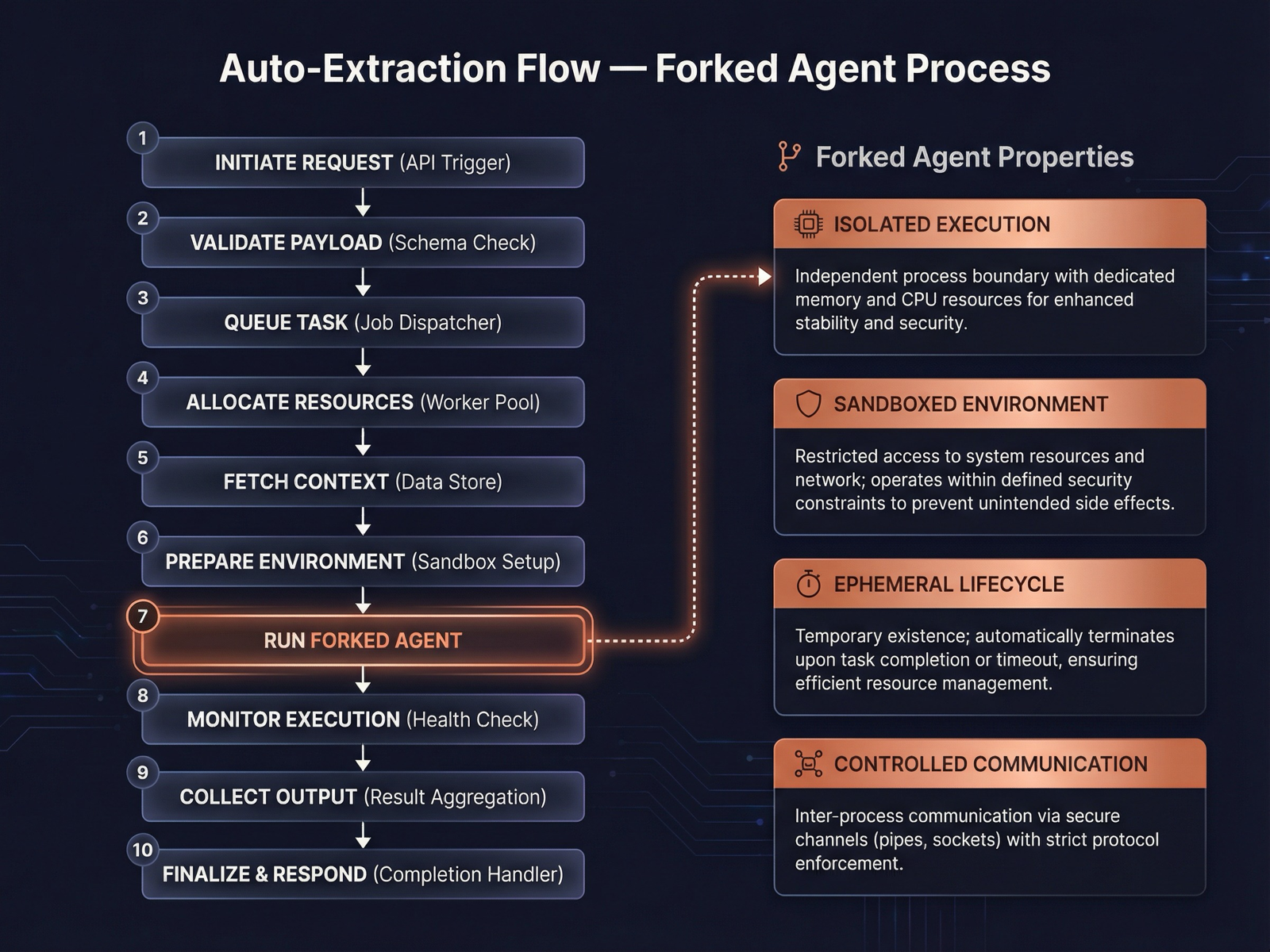
触发时机
在 handleStopHooks 中,当模型产生最终响应(无工具调用)时触发。
关键源码 src/services/extractMemories/extractMemories.ts
完整提取流程
1. 模型完成回复(无 tool_use)
↓
2. executeExtractMemories() 被调用
↓
3. 守卫检查:
- 是主代理?(子代理不提取)
- 功能门控开启?
- 自动记忆启用?
- 非远程模式?
- 没有并行提取在进行?
↓
4. 频率控制:
turnsSinceLastExtraction++
if < tengu_bramble_lintel → 跳过
↓
5. 互斥检查:
主代理自己写了记忆?→ 跳过,推进游标
↓
6. 扫描现有记忆目录(scanMemoryFiles)
生成清单(formatMemoryManifest)
↓
7. 构建提取提示词(buildExtractAutoOnlyPrompt)
↓
8. 运行分叉代理(runForkedAgent)
- 共享父会话的提示词缓存
- 最多 5 个 turn
- 限制工具权限
↓
9. 提取写入的文件路径
推进游标到最新消息
↓
10. 通知用户:"Memory updated in ..."分叉代理(Forked Agent)
自动提取使用 runForkedAgent — 这是对主会话的完美分叉:
- 共享提示词缓存:避免重复的 API 缓存创建费用
- 隔离执行:不影响主会话的消息历史
- 受限工具:只允许 Read、Grep、Glob、只读 Bash、以及对记忆目录的 Edit/Write
- 不记录转录:防止与主线程的竞争条件
工具权限(createAutoMemCanUseTool)
✅ 允许:Read, Grep, Glob(无限制)
✅ 允许:Bash(仅只读命令:ls, find, grep, cat, stat...)
✅ 允许:Edit/Write(仅 auto-memory 目录内)
❌ 拒绝:MCP, Agent, 非只读 Bash, 其他写操作互斥机制
主代理和提取代理是互斥的:
function hasMemoryWritesSince(messages, sinceUuid): boolean {
// 扫描 sinceUuid 之后的所有 assistant 消息
// 如果有任何 Edit/Write 的 tool_use 指向 auto-memory 目录
// → return true(跳过提取,推进游标)
}这避免了重复保存:主代理已经写了记忆时,后台提取直接跳过。
合并机制
如果前一次提取还在运行:
- 新的上下文被暂存(
pendingContext) - 旧提取完成后,立即启动一次尾部提取
- 尾部提取只处理两次调用之间新增的消息
五、智能记忆检索
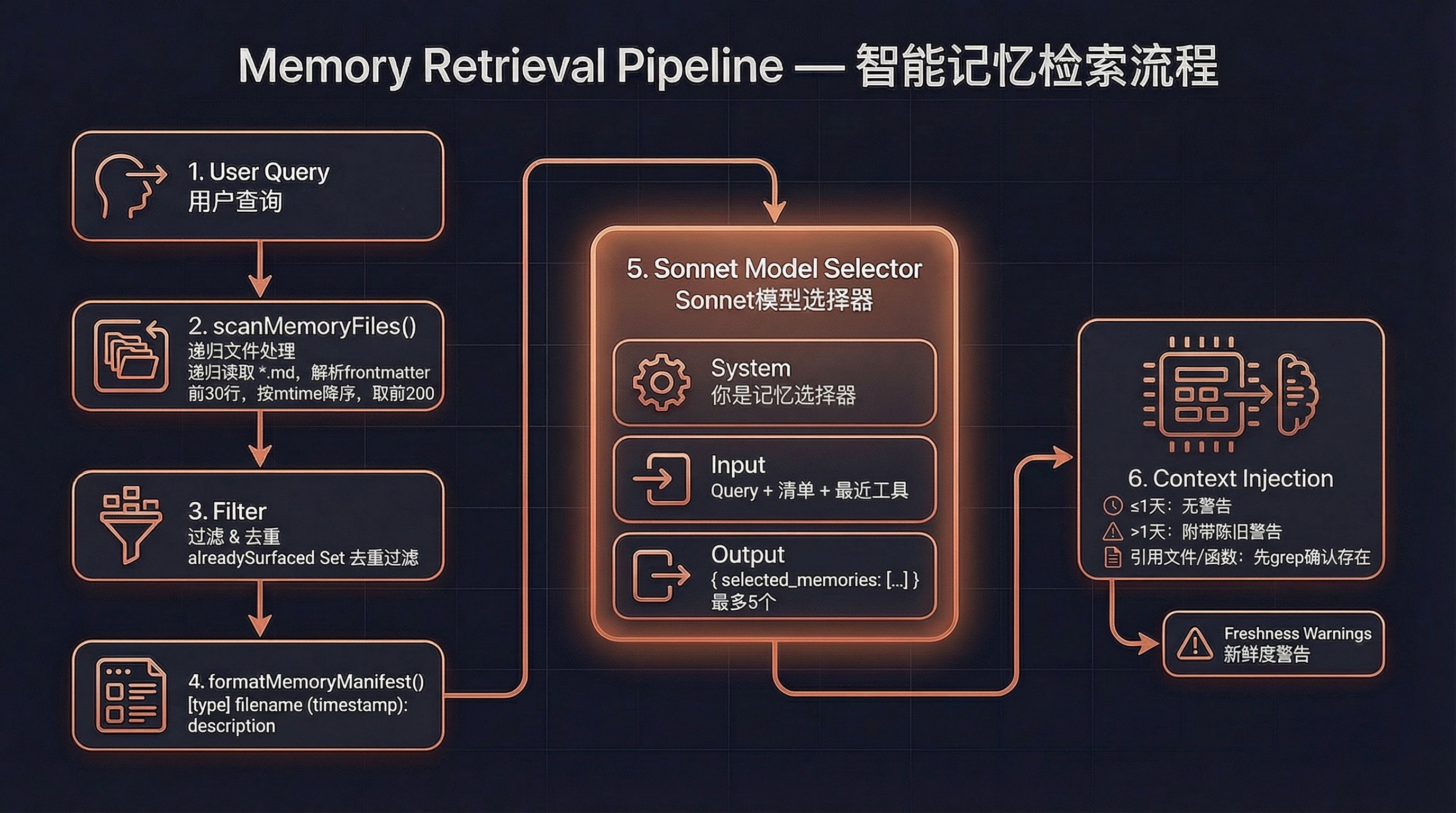
工作原理
每次用户发送查询时,findRelevantMemories() 被触发:
1. scanMemoryFiles(memoryDir)
- 递归读取所有 .md 文件(排除 MEMORY.md)
- 解析 frontmatter(前 30 行)
- 按修改时间降序排序
- 最多 200 个文件
↓
2. 过滤已展示过的记忆(alreadySurfaced)
↓
3. 格式化清单(formatMemoryManifest)
- [type] filename (ISO timestamp): description
↓
4. Sonnet 模型选择(sideQuery)
- 系统提示:你是记忆选择器...
- 用户消息:Query + Available memories + Recently used tools
- 输出:JSON { selected_memories: string[] }
- 最多选 5 个
↓
5. 返回选中记忆的 { path, mtimeMs }Sonnet 选择器的提示词
你正在选择对 Claude Code 处理用户查询有用的记忆。
你将收到用户查询和可用记忆文件列表(含文件名和描述)。
返回最多 5 个明确有用的记忆文件名。
- 不确定是否有用就不要选
- 没有明确有用的就返回空列表
- 如果提供了最近使用的工具列表,不要选这些工具的使用文档
(但 DO 选择关于这些工具的警告/陷阱/已知问题)新鲜度警告
选中的记忆在注入上下文时会附带新鲜度信息:
function memoryFreshnessText(mtimeMs: number): string {
const d = memoryAgeDays(mtimeMs)
if (d <= 1) return '' // 今天/昨天:无警告
return `This memory is ${d} days old. Memories are point-in-time observations...
Verify against current code before asserting as fact.`
}六、记忆扫描详解
scanMemoryFiles()
关键设计:单次遍历(read-then-sort),避免双重 stat 系统调用。
async function scanMemoryFiles(memoryDir, signal): Promise<MemoryHeader[]> {
const entries = await readdir(memoryDir, { recursive: true })
const mdFiles = entries.filter(f => f.endsWith('.md') && basename(f) !== 'MEMORY.md')
// 并行读取所有文件的 frontmatter(前 30 行)
const headerResults = await Promise.allSettled(
mdFiles.map(async (relativePath) => {
const { content, mtimeMs } = await readFileInRange(filePath, 0, 30)
const { frontmatter } = parseFrontmatter(content)
return { filename, filePath, mtimeMs, description, type }
})
)
// 过滤成功的、按时间降序排序、取前 200
return fulfilled.sort((a, b) => b.mtimeMs - a.mtimeMs).slice(0, 200)
}formatMemoryManifest()
生成供 Sonnet 或提取代理消费的清单格式:
- [feedback] testing_policy.md (2026-03-15T10:30:00.000Z): 集成测试用真实数据库
- [user] role.md (2026-03-14T08:00:00.000Z): 数据科学家,关注日志
- [project] freeze.md (2026-03-10T15:00:00.000Z): 3/5 起合并冻结七、代理记忆(Agent Memory)

子代理(通过 Agent 工具启动的)有独立的三级记忆系统:
| 作用域 | 路径 | 说明 |
|---|---|---|
| user | ~/.claude/agent-memory/{agentType}/ | 全局用户级 |
| project | .claude/agent-memory/{agentType}/ | 项目级(提交到 VCS) |
| local | .claude/agent-memory-local/{agentType}/ | 本地级(不提交) |
代理记忆与主记忆的差异:
- 无 MEMORY.md 索引步骤(
skipIndex = true) - 直接写文件即可,无需两步操作
- 各代理类型隔离(explorer、planner 等各有各的目录)
八、团队记忆同步
当 TEAMMEM feature flag 开启时:
目录结构
~/.claude/projects/{hash}/memory/
├── MEMORY.md ← 个人记忆索引
├── user_*.md ← 个人记忆
└── team/ ← 团队共享目录
├── MEMORY.md ← 团队记忆索引
└── *.md ← 团队记忆同步 API
GET /api/claude_code/team_memory?repo={owner/repo} ← 拉取
PUT /api/claude_code/team_memory?repo={owner/repo} ← 推送同步语义
- Pull:服务器内容覆盖本地文件
- Push:仅上传内容哈希不同的键(delta 上传)
- 删除不传播:本地删除不会删除远程
- 限制:单文件最大 250KB,上传体最大 200KB(分批)
团队 vs 个人的路由规则
在 memoryTypes.ts 中,每种类型有 <scope> 指导:
| 类型 | 默认作用域 |
|---|---|
| user | 始终个人 |
| feedback | 默认个人,项目级规范放团队 |
| project | 偏向团队 |
| reference | 通常团队 |
九、关键常量速查
// 索引文件
ENTRYPOINT_NAME = 'MEMORY.md'
MAX_ENTRYPOINT_LINES = 200
MAX_ENTRYPOINT_BYTES = 25_000
// 扫描
MAX_MEMORY_FILES = 200
FRONTMATTER_MAX_LINES = 30
// 路径
AUTO_MEM_DIRNAME = 'memory'
// 提取
maxTurns = 5 // 分叉代理最多 5 个 turn
// 检索
最多返回 5 个相关记忆十、数据流总览
┌─────────────────────────────────────────────────────┐
│ 会话启动 │
│ │
│ loadMemoryPrompt() │
│ → ensureMemoryDirExists() │
│ → buildMemoryLines() + MEMORY.md 内容 │
│ → 注入系统提示词 │
└────────────────────────┬────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ 用户提问 │
│ │
│ findRelevantMemories() │
│ → scanMemoryFiles() [扫描 + frontmatter] │
│ → Sonnet 选择最多 5 个相关记忆 │
│ → 注入对话上下文 + 新鲜度警告 │
└────────────────────────┬────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ Claude 回复 │
│ │
│ 模型可能直接写记忆(遵循系统提示词指导) │
│ 或者不写 → 触发后台提取 │
└────────────────────────┬────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ 后台自动提取 │
│ │
│ executeExtractMemories() │
│ → 互斥检查(主代理已写?跳过) │
│ → 构建提取提示词 + 记忆清单 │
│ → runForkedAgent() [共享缓存, 限制工具, 5 turns] │
│ → 写入新记忆文件 + 更新 MEMORY.md │
│ → 通知用户 │
└────────────────────────┬────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ 后台记忆整合(AutoDream) │
│ │
│ executeAutoDream() [每 24h + 5个会话触发] │
│ → 五重门控检查(开关/时间/节流/会话/锁) │
│ → buildConsolidationPrompt() │
│ → runForkedAgent() [只读 Bash, 仅记忆目录写入] │
│ → 四阶段:定向 → 收集 → 整合 → 修剪 │
│ → 合并重复 / 修正过时 / 压缩索引 │
│ → 通知用户:"Improved N memories" │
│ │
│ 详见 03-autodream.md │
└─────────────────────────────────────────────────────┘